什么是tcp/ip协议
tcp/ip是2个协议,tcp是运输端协议,ip是网络端协议,这2个协议一般一起使用的。ip协议是来确定和找到地址的,tcp则是具体的传输信息的工作。
tcp的三次握手和四次挥手协议
理解这个过程首先要知道tcp的2个序号和3个标志位的含义。
seq:表示传输数据的序号。tcp传输时每一个字节都有序号,发送时会把第一个序号发过去。接收端通过序号判断数据是否完整,如果不完整则重发。
ack:表示确认号,接受端表示数据已经完整接受,向发送端发送确认号。表示希望接受到数据的编号。一般为接受端报文最后的序号+1.
ACk:表示确认位。只有ACK=1时ack才会起作用。正常通信时ACK=1,第一次的话没有接收方确认是0.
SYN:这个是同步标志位,当SYN=1,ACK=0时表示这是个连接请求报文段,握手完成后SYN标志位为1
FIN:FIN=1表示数据已经发送完要求释放运输连接。
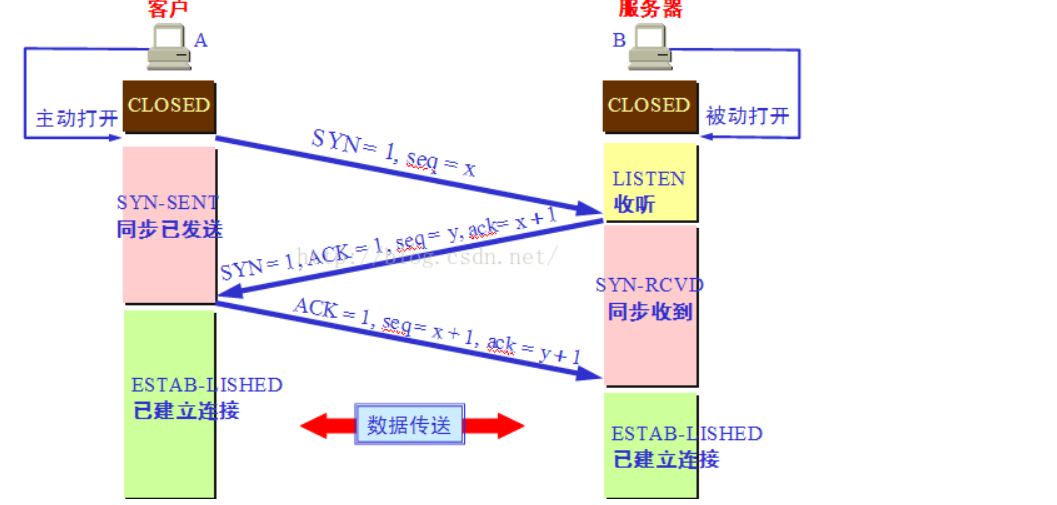
简述下3次握手和四次挥手
三次握手
1.客户端向服务端发送连接请求包,ACk位为0,SYN为1,seq=X,ACk是因为没有接受到确认信息故为0,因此需要同步标志位来确认其为有效连接。
2.服务端向客户端发送确认信息:标识位SYN=1,ACK=1,希望收到的下个信息的序号为ack=x+1;自身的seq序号为y.
3.客户端向服务端发送确认报文,ACK=1,SYN=1,ack=y+1,seq=x+1。
为何需要三次握手?
第一次,服务端知道自己接受数据没问题,第二次,客户端知道自己自己发送数据和接受数据没问题,第三次服务端知道自己发送数据没问题。然后,数据开始发送。
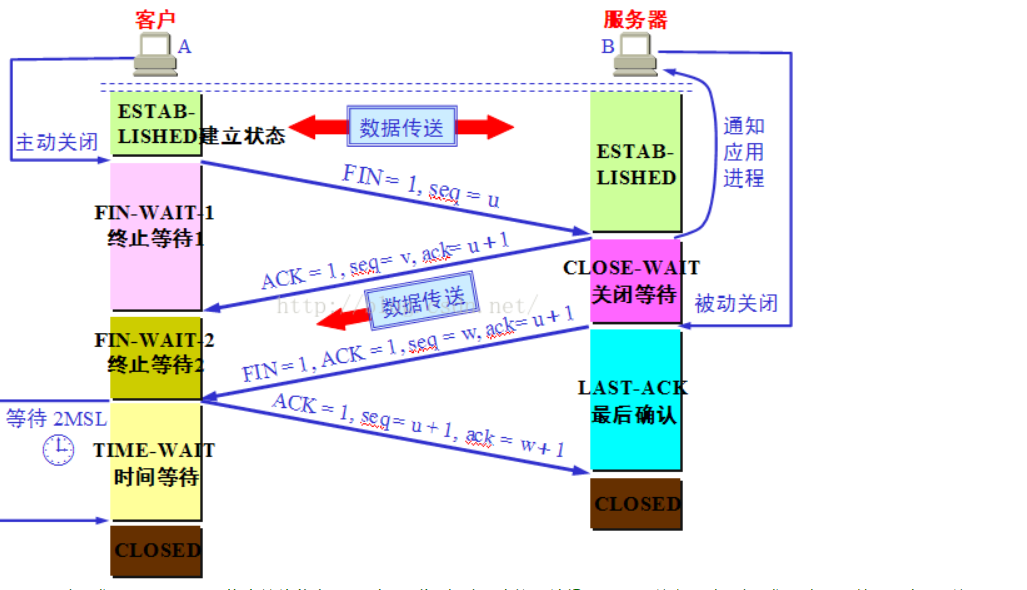
四次挥手
1.客户发送FIN=1,seq=x,来像服务器发送终止请求。
2.服务端接受到FIN后,发送一个ACK=1,seq=y,ACK=x+1.
3.关闭服务端到客户端的连接,且发送一个FIN给客户端。
4.客户端收到FIN后,且发送一个ACK=1,seq=x+1,ack=y+1.
简而言之这样的:
第一次客户端发送一个fin,表示自己数据发完了,服务端收到后,若是数据没有发送完,就发送一个ack,表示,已经收到你的请求,但是服务端数据没有发送完,继续发送数据,等到数据发送完了,就发送一个fin,客户端收到fin后就发送一个ack,表示确认收到,服务端就可以关闭连接了。但是客户端还是要等一个周期时间,如果客户端发送ack丢失了,服务端没有收到就会继续发送fin,直到收到信息后,才关闭,而客户端在一定周期内没有收到信号也关闭。
为何是结束是4次握手?
数据可能没有发送完。如果都是同时发送完了,那么也是3次握手,3次握手是由于没有数据传送
注意到每一次连接都要消耗3次握手和4次握手,
故有了tcp长连接和短连接,http的长连接和短连接实际上就是tcp的.
短连接:就是一次简单的tcp连接,数据发送完直接关闭。连接→数据传输→关闭连接
长连接:就是在一次连接内多次发送数据包,中间若是没有数据那么靠心跳保活协议维护, 连接→数据传输→保持连接(心跳)→数据传输→保持连接(心跳)→……→关闭连接
这样子就减少了多次连接所消耗的握手